Użyteczność oprogramowania analitycznego w badaniach jakościowych – Atlas.ti

Raporty z badań społecznych nie muszą być opasłymi tomami – nawet jeżeli opierają się na danych jakościowych, wciąż mogą być zwięzłe i konkretne. Dlatego tak ważne jest opanowanie trudnej sztuki organizacji materiału w badaniach jakościowych. Używany w Dziale Analiz Strategicznych PW program Atlas.ti, wspiera nas na każdym etapie prac: porządkowaniu, analizie i interpretacji wyników.
W trosce o jakość badań jakościowych
Materiał w badaniach jakościowych jest zwykle obszerny. Przykładowo, godzinny wywiad indywidualny może sięgnąć 8 stron maszynopisu, natomiast zapis 90-minutowego zogniskowanego wywiadu grupowego dwa razy tyle. Przy kilkudziesięciu wywiadach mamy do czynienia z setkami stron litego tekstu. Zapoznanie się materiałem może dać złudzenie, że „wiadomo, co w nim jest” oraz jaka jest odpowiedź na pytania badawcze. Tymczasem należy oddzielić przekonania badacza od faktów i badać materiał możliwie obiektywnie, by chronić istotne wartości definiujące badania jakościowe: rzetelność procesu i trafność odpowiedzi (Flick 2011).
Podobnie jak w analizie danych liczbowych, w analizie materiału jakościowego stosowane są określone metodyki i scenariusze analiz, określające kolejne działania. Zależnie od przedmiotu badań, jako dane są traktowane jednostki językowe (słowa, zdania, akapity) lub graficzne (zdjęcia, ilustracje). Dane są porządkowane i klasyfikowane, co pozwala budować określone zestawienia. Analiza pozwala m.in. na zliczanie częstości oraz określanie relacji, np. współwystępowania danych określonego typu i ich wzajemnych zależności. Obiektywna analiza prowadzi do uprawnionej interpretacji danych i wnioskowania, odległego od uznaniowych interpretacji.
Oprogramowanie usprawnia proces porządkowania danych i poszukiwania zależności, zapewnia też przejrzystość procesu analizy i przez to zwiększa jej rzetelność.
Organizacja materiału badawczego w oprogramowaniu Atlas.ti
Proces analityczny w Atlas.ti odzwierciedla pracę z materiałem w ujęciu teorii ugruntowanej: etykietowanie, tj. kodowanie i kategoryzowanie wątków, tworzenie not teoretycznych, stałe porównywanie fragmentów, łączenie wątków wspólnych, szukanie sprzeczności. To iteracyjny proces, który prowadzi do stałego analizowania materiału – powracania do wybranych fragmentów i analizowania ich powtórnie, aż problem badawczy zostanie wyczerpany, a badacz będzie miał podstawy, by spisać wnioski w formie raportu (Niedbalski 2014).
Próbę w badaniu stanowią Dokumenty Pierwotne (Primary Documents), czyli np. transkrypcje wywiadów. Przy wgrywaniu transkrypcji do programu, warto jest zwrócić uwagę, jak są opisane pliki i uzupełnić informacje, które mogą być dla nas istotne w analizie, np. miejsce wykonania wywiadu. Pozwoli to przypisać wybrane zmienne niezależne lub inne parametry definiujące jednostkę, przydatne potem na etapie analizy.
Kodowanie pozwala oznaczyć w materiałach wszystkie wątki istotne z punktu widzenia badań. Etykietowanie wybranych cytatów (Quotations) z użyciem kodów (Codes) jest podstawowym narzędziem porządkowania materiału. Możemy w dalszych analizach posługiwać się cytatem z wywiadu lub uogólnioną kategorią (kodem), której dotyczy dana wypowiedź. Trudno przecenić rolę tego etapu, ponieważ jakość analizy jest bezpośrednio związana z jakością wprowadzonych kodów. Sukces opiera się na spójności i konsekwencji w stosowaniu obranej metody działania.
Zdj. 1. Fragment analizowanego materiału z oznaczonymi cytatami (kodami)

Strategii działania jest kilka. Kody można budować na trzy sposoby: otwarte (wpisać nowy), z listy (wybrać istniejący) lub in vivo (zakodować materiał dosłownie). Dlatego przy kilkuosobowych zespołach badawczych praktycznie jest połączyć podejście dedukcyjne z indukcyjnym. Przykładowo, na podstawie pytań badawczych można sformułować grupy problemowe, do których są przyporządkowane kategorie niższego rzędu. Dzięki temu zależności między poszczególnymi pojęciami można w efekcie przestawić graficznie (drzewo kodowe) obejmujące kody i rodziny kodów, ale też zależności, np. „zawiera się w”, „jest sprzeczne z”. Warto dodawać do kodów definicje i przykłady kontekstów użycia (książka kodowa). W opisaniu wielokrotnie pojawiających się kodów (np. słowa kluczowe) można użyć opcji autokodowania, co przyspieszy pracę.
Zdj. 2. Przykładowe zależności istotnych kategorii w badaniach (drzewo kodowe)
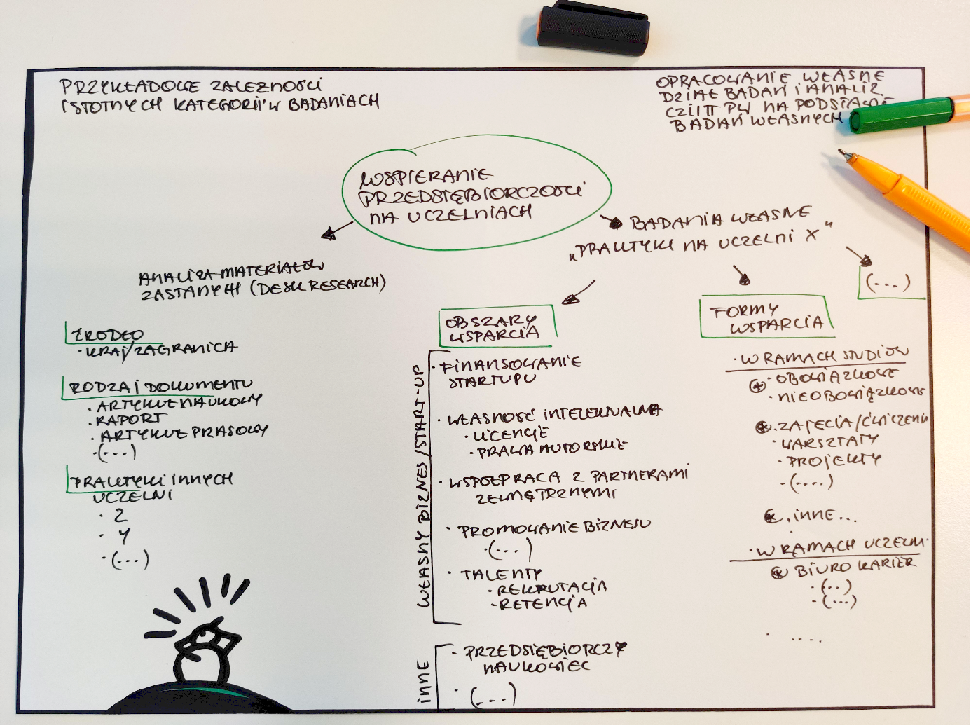
Dodatkowo, dobrze by badacze mieli możliwość wprowadzania nowych kodów, gdy natkną się na ciekawy i istotny badawczo wątek. Nowe propozycje mogą zostać odrębne lub scalone z innymi kodami. Ponadto, materiał powinien być stale dyskutowany przez badaczy, a drzewo kodowe czyszczone z redundancji (np. zbędnych powtórzeń). To czasochłonne działanie, ale warto je wykonać, ponieważ dobra siatka kodów pozwala sprawnie odnaleźć potrzebne fragmenty.
Warto korzystać z narzędzia wolnych notatek (mema), które pozwala uporządkować natłok przemyśleń i pomysłów pojawiających się podczas analizowania materiału i które można wykorzystać na dalszym etapie pracy. Wolne notatki można przypisywać nie tylko do cytatu, ale i do dokumentu, co pozwala na precyzyjne zarządzanie pomysłami (Friese 2009). To naprawdę miła odmiana od morza fiszek, notatek i karteczek samoprzylepnych.
Analiza i interpretacja
Program umożliwia generowanie szeregu zestawień i wizualizacji, z których warto wspomnieć o najważniejszych. Dzięki funkcji zapytań (query tool) możemy wygenerować istotne dla analiz zestawienie z użyciem operatorów logicznych (OR, AND, ONE OF, NOT), oraz zależności semantycznych i przestrzennych (m.in. współwystępowanie kodów; zawieranie się w; nakładanie się; kody, które się regularnie poprzedzają lub następują po sobie). Ponadto program umożliwia zliczanie częstości występowania określonych słów czy generowanie chmury tagów.
Tabela kodów i dokumentów pozwala na zestawienie występowania poszczególnych wątków w danych jednostkach. Na przykład możemy zestawić wybrany kod z dokumentami uporządkowanymi według zmiennych niezależnych respondentów (np. region, wykształcenie). Działanie pozwala na generowanie zestawień o różnych poziomach szczegółowości (kod, rodzina kodów vs pojedynczy dokument lub grupa). W tabeli można prezentować dane liczbowe, dotyczące powiazań kodów z danym dokumentem: binarnie (czy występuje czy nie), liczbowo lub procentowo, co pozwala na uporządkowanie według określonych parametrów. Całość można eksportować do Excela i dalej edytować. Podobnie działa tabela współwystępowania kodów, gdzie można zestawić wybrane kody / grupy kodów ze sobą.
Odnośniki
- Flick, U. 2011. Jakość w badaniach jakościowych. Wyd. Naukowe PWN.
- Friese S. 2009. Working Effectively with Memos in ATLAS.t. ATLAS.ti Library.
- Niedbalski J., 2014. Zastosowanie oprogramowania Atlas.ti i NVivo w realizacji badań opartych na metodologii teorii ugruntowanej. W: Przegląd Socjologii Jakościowej, 2014, Tom X Numer 2.
Przykłady praktycznej realizacji badań społecznych są dostępne w zakładce Raporty i publikacje, m.in:
- Potrzeby i oczekiwania młodych naukowców związane z rozwojem zawodowej kariery naukowej. Raport z badania społecznego;
- Badania społeczne w zakresie jakości kształcenia w Politechnice Warszawskiej.
Zespół badaczy
W DAS PW realizujemy badania jakościowe w Pracowni fokusowej i wygodnych salach warsztatowych. Dostęp do oprogramowania Atlas.ti jest możliwy w każdej z pracowni, również dzięki badaczom i badaczkom doświadczonym w jego używaniu.
Autorką artykułu jest dr Aleksandra Wycisk, a grafikę stworzono w narzędziu SI: Adobe Firefly.
